rath.llm#
Provider options, request/response types, OpenAI and Anthropic clients, streaming deltas, embedding/VLM clients, retry, budget accounting, and response normalization.
Source#
Module |
Source |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Public contract#
Provider#
Provider stores OpenAI-compatible client identity plus model, sampling, tool, and provider-specific parameters required by the loop. It does not contain messages or tools; the session loop constructs those.
Field category |
Fields |
|---|---|
client identity |
|
model |
|
sampling |
|
penalties |
|
tools/output |
|
OpenAI options |
|
retry/budget |
|
Provider.from_config(name=None, **overrides) builds a provider from ~/.openrath/config.json; explicit overrides win over the file.
Client#
from rath.llm import Provider, RathOpenAIChatClient, chat_client_for
provider = Provider(api_key="sk-...", base_url=None, model="gpt-5.5")
client = RathOpenAIChatClient(provider)
response = client.complete(request)
anthropic = Provider(provider_kind="anthropic", model="claude-sonnet-4-5")
client = chat_client_for(anthropic)
chat_client_for(provider) dispatches through the registry. Built-in kinds are OpenAI-compatible (None or "openai") and Anthropic ("anthropic"). Third-party adapters can call register_chat_client(kind, factory).
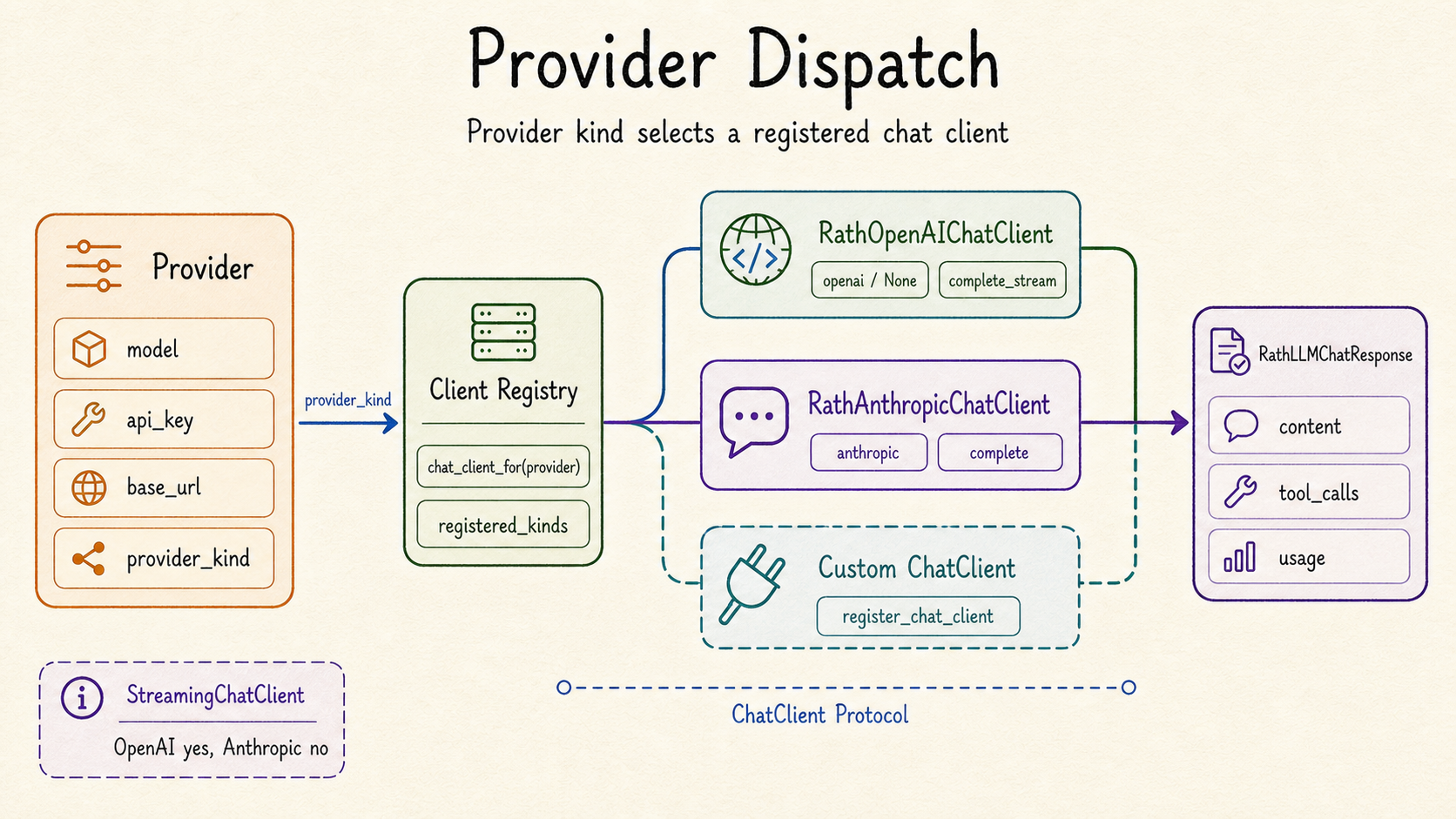
Provider.provider_kind selects a registered chat-client factory; new provider
kinds integrate at the registry boundary instead of changing the session loop.#
Request and response DTOs#
Type |
Description |
|---|---|
|
Chat |
|
Function-style tool schema. |
|
OpenAI-compatible request kwargs. |
|
Normalized completion response. |
|
Normalized streaming delta. |
|
Single choice. |
|
Assistant message, including tool calls. |
|
Tool call structure. |
|
Usage statistics. |
Embeddings and VLM#
v1.2 adds first-class provider wrappers for non-chat model calls. They use the same config style as Provider, but keep their public surface narrow so memory backends and visual tools do not depend on chat-completion internals.
API |
Config key |
Default behavior |
|---|---|---|
|
|
Falls back through the configured default chat provider credentials and uses |
|
OpenAI-compatible embedding endpoint |
Returns embedding vectors for text input. |
|
|
Requires an explicit VLM provider entry or overrides. |
|
OpenAI-compatible vision/chat endpoint |
Sends text plus image inputs through a VLM-compatible model. |
Create arguments#
to_create_kwargs(req, default_model=...) converts the internal request to non-streaming OpenAI SDK kwargs. RathOpenAIChatClient.complete_stream(...) uses the streaming sibling and yields RathLLMStreamDelta chunks.
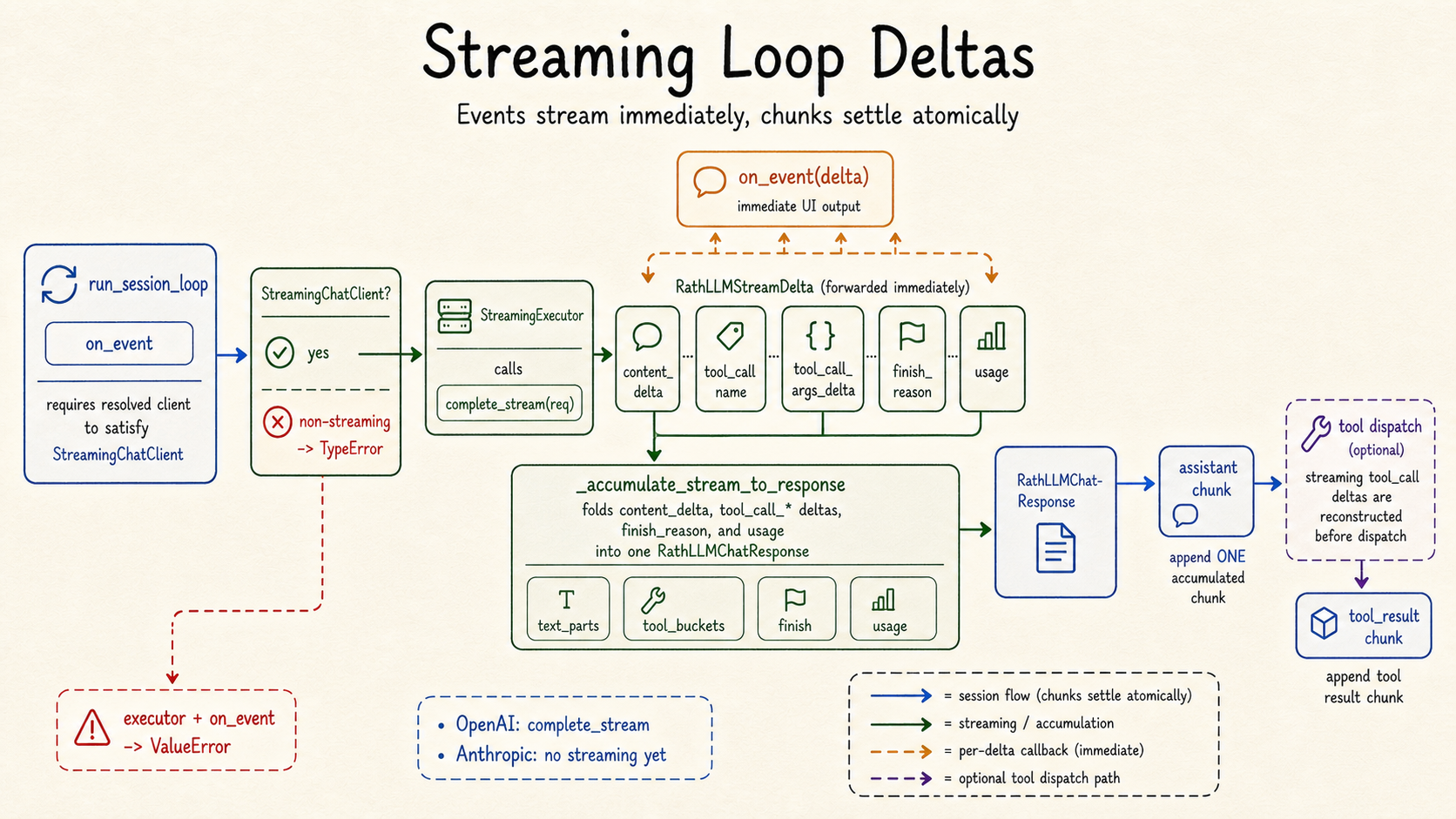
Streaming forwards deltas to on_event while the session loop still appends one
durable assistant chunk per completed model round.#
Behavior |
Description |
|---|---|
model selection |
Uses |
tool schema |
Converts |
stream |
Non-streaming kwargs force |
extra args |
Merges |
Environment and config fallback#
Client |
Resolution order |
|---|---|
OpenAI API key |
|
OpenAI base URL |
|
OpenAI model |
|
Anthropic API key |
|
Anthropic base URL |
|
Anthropic model |
|
Legacy Azure endpoints are routed through openai.AzureOpenAI; /openai/v1 endpoints use the standard OpenAI client.
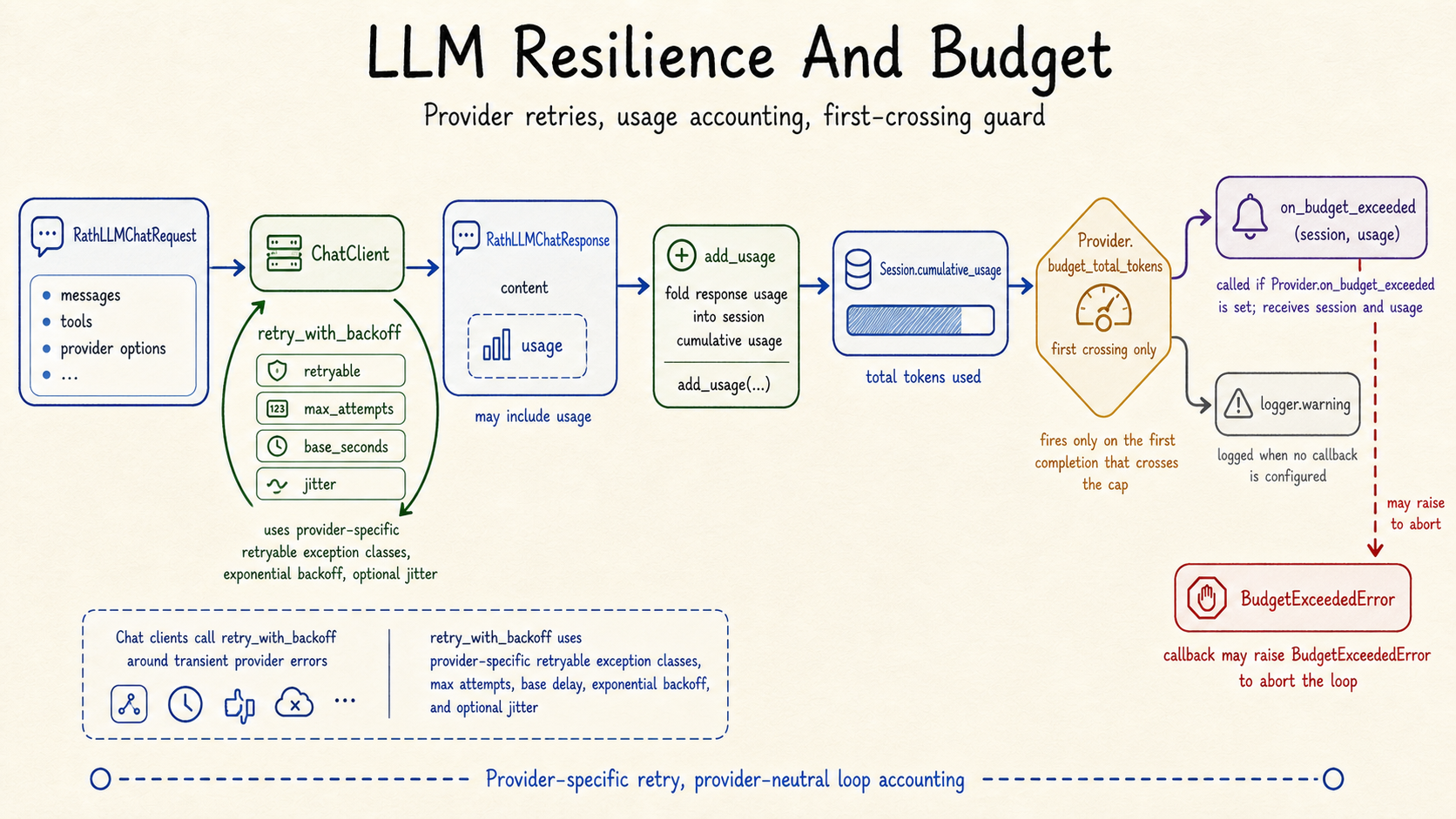
Retries, usage aggregation, and budget checks sit around provider calls without
changing the public Session and Provider API shape.#
Autodoc#
- class rath.llm.Provider(*, base_url: str | None = None, api_key: str | None = None, model: str | None = None, temperature: float | None = None, top_p: float | None = None, max_completion_tokens: int | None = None, max_tokens: int | None = None, stop: str | list[str] | None = None, n: int | None = None, seed: int | None = None, frequency_penalty: float | None = None, presence_penalty: float | None = None, tool_choice: ~typing.Literal['auto', 'none', 'required'] | ~typing.Mapping[str, ~typing.Any] | None = None, parallel_tool_calls: bool | None = None, response_format: dict[str, ~typing.Any] | None = None, logit_bias: dict[str, int] | None = None, logprobs: bool | None = None, top_logprobs: int | None = None, reasoning_effort: str | None = None, verbosity: str | None = None, metadata: dict[str, str] | None = None, user: str | None = None, store: bool | None = None, service_tier: str | None = None, extra_create_args: ~typing.Mapping[str, ~typing.Any] = <factory>, retry_max_attempts: int | None = None, retry_base_seconds: float | None = None, budget_total_tokens: int | None = None, on_budget_exceeded: ~typing.Callable[[...], None] | None = None, provider_kind: ~typing.Literal['openai', 'anthropic'] | None = None)[source]#
LLM routing for
run_session_loop(nomessages/tools).base_url,api_key, andmodelconfigure the HTTP client built fromprovider_kind(OpenAI-compatible or Anthropic). Other fields mirrorRathLLMChatRequest(excluding what the loop fills in).api_keymay be omitted when callers supply a customexecutorthat never instantiates a defaultRathOpenAIChatClientorRathAnthropicChatClient.- classmethod from_config(name: str | None = None, *, store: ConfigStore | None = None, **overrides: Any) Provider[source]#
Build a
Providerfrom~/.openrath/config.json.Looks up
name(orllm.default_providerwhenname=None) underllm.providers, then constructs aProviderwhose fields come from the entry. Any explicitoverrideswin — pass e.g.Provider.from_config("openai-main", api_key="ad-hoc")to rotate one field without touching the on-disk file.Lazy-imports
rath.configso thatimport rath.llmnever touches the filesystem.Raises
KeyErrorwhen the named provider is missing; the message lists what is available.
- class rath.llm.RathOpenAIChatClient(provider: Provider)[source]#
Thin client around
openai.OpenAIchat completions (sync + streaming).Empty
Provider.api_key/Provider.base_urlfall back to environment variables (set them in the shell or viarath.config):base_url:OPENAI_BASE_URLthenAZURE_OPENAI_ENDPOINT.api_key:OPENAI_API_KEYfor OpenAI-compatible endpoints; for*.azure.comendpoints the order becomesAZURE_OPENAI_API_KEY→AZURE_API_KEY→OPENAI_API_KEY.
Azure endpoints exposing the new
/openai/v1surface speak plain OpenAI Chat Completions, so the vanilla SDK is used. Legacy Azure endpoints (/openaiwithout/v1) are routed throughopenai.AzureOpenAIwithapi_versiontaken fromOPENAI_API_VERSION(default2024-10-21).- complete(req: RathLLMChatRequest) RathLLMChatResponse[source]#
Run
chat.completions.createand normalize the response.Transient errors (rate limit, connection, timeout, server 5xx) are retried with exponential backoff per
Provider.retry_max_attemptsandProvider.retry_base_seconds.
- complete_stream(req: RathLLMChatRequest) Iterator[RathLLMStreamDelta][source]#
Yield
RathLLMStreamDeltafor each chunk of a streaming completion.Transient errors during the initial
createcall are retried; once the iterator starts producing chunks, retries are no longer possible (the stream is committed).
- class rath.llm.RathAnthropicChatClient(provider: Provider)[source]#
Thin client around
anthropic.Anthropicmessages API (sync + streaming).- complete(req: RathLLMChatRequest) RathLLMChatResponse[source]#
Run
messages.createand normalize the response.Transient errors are retried per
Provider.retry_max_attempts/Provider.retry_base_seconds. The retryable set is the Anthropic-flavored quadruple (RateLimitError,APIConnectionError,APITimeoutError,InternalServerError).
- complete_stream(req: RathLLMChatRequest) Iterator[RathLLMStreamDelta][source]#
Yield
RathLLMStreamDeltafor each event frommessages.stream.Transient errors during the initial
streamopen are retried; once the iterator starts producing events, retries are no longer possible.
- class rath.llm.EmbeddingProvider(*, model: str, base_url: str | None = None, api_key: str | None = None, dimensions: int | None = None, retry_max_attempts: int | None = None, retry_base_seconds: float | None = None)[source]#
Routing + credentials for an OpenAI-compatible embeddings endpoint.
The chat
Provider(inrath.llm.provider) is intentionally not reused: embedding endpoints frequently live under a different base_url / model namespace even when the api_key is shared.- dimensions: int | None#
When set, request a truncated/projected embedding vector. The OpenAI SDK passes this as
dimensions=.Nonemeans use the model’s native dimension.
- classmethod from_config(name: str | None = None, *, store: ConfigStore | None = None, **overrides: Any) EmbeddingProvider[source]#
Build an
EmbeddingProviderfrom~/.openrath/config.json.Lookup order:
nameif given.llm.embedding_providerif set.llm.default_provider(chat fallback) — uses its credentials but replacesmodelwithDEFAULT_EMBEDDING_MODELsince the chat model is unsuitable for embeddings.
Raises
KeyErroronly whennameis given explicitly and the entry is missing.
- class rath.llm.RathOpenAIEmbeddingClient(provider: EmbeddingProvider)[source]#
Thin wrapper around
openai.OpenAI().embeddings.create.Construct once per
EmbeddingProvider; the underlying SDK client is created up-front and reused across calls.
- class rath.llm.VLMProvider(*, model: str, base_url: str | None = None, api_key: str | None = None, max_tokens: int | None = 512, temperature: float | None = None, retry_max_attempts: int | None = None, retry_base_seconds: float | None = None)[source]#
Routing + credentials for an OpenAI-compatible vision endpoint.
- classmethod from_config(name: str | None = None, *, store: ConfigStore | None = None, **overrides: Any) VLMProvider[source]#
Build a
VLMProviderfrom~/.openrath/config.json.Lookup order:
nameif given.llm.vlm_providerif set.
Unlike
EmbeddingProvider, there is no fallback tollm.default_provider: a chat model is rarely a vision model, and silently falling back would produce confusing 400 errors at first use. RaisesKeyErrorinstead.
- class rath.llm.RathOpenAIVLMClient(provider: VLMProvider)[source]#
Thin wrapper turning
(image, prompt) -> captioninto a chat call.
- class rath.llm.ChatClient(*args, **kwargs)[source]#
Minimal synchronous chat-completion contract.
Implementations must keep
completeblocking and side-effect-free beyond the network call itself; retries / token accounting / budget handling are layered above in the session loop.
- class rath.llm.StreamingChatClient(*args, **kwargs)[source]#
A
ChatClientthat also supports streaming completions.run_session_loop()accepts any object satisfying this Protocol whenon_eventis provided. Both OpenAI and Anthropic adapters implement it.
- rath.llm.chat_client_for(provider: Provider) ChatClient[source]#
Return the
ChatClientforprovider.provider_kind.provider.provider_kind=Nonedefaults to"openai". Unknown kinds raiseValueErrorlisting what is currently registered.
- rath.llm.register_chat_client(kind: str, factory: Callable[[Provider], ChatClient]) None[source]#
Register
factory(provider) -> ChatClientunderkind.Overwrites any previous registration silently — late imports therefore win. Built-in kinds (
"openai","anthropic") are registered when their subpackages are imported byrath.llm.
- rath.llm.registered_kinds() tuple[str, ...][source]#
Snapshot of currently registered kinds (useful for diagnostics / tests).
- rath.llm.to_create_kwargs(req: RathLLMChatRequest, *, default_model: str | None) dict[str, Any][source]#
Map
RathLLMChatRequesttoOpenAI.chat.completions.createkwargs.Non-streaming only:
streamis forced toFalseafterextra_create_argsare merged.stream=Truein extras raisesValueError.
- rath.llm.normalize_chat_completion(completion: ChatCompletion) RathLLMChatResponse[source]#
Convert an SDK
ChatCompletionintoRathLLMChatResponse.
- rath.llm.build_anthropic_kwargs(req: RathLLMChatRequest, *, default_model: str | None) dict[str, Any][source]#
Translate
RathLLMChatRequestintomessages.createkwargs.default_modelmirrorsto_create_kwargs(): it’s used when neither the request nor the provider supplies a model name.
- rath.llm.build_anthropic_stream_kwargs(req: RathLLMChatRequest, *, default_model: str | None) dict[str, Any][source]#
Same kwargs as
build_anthropic_kwargs()formessages.stream.Anthropic’s
messages.stream(**kwargs)uses the same shape asmessages.create; there is nostream=Trueflag. Named entrypoint parallel torath.llm.openai.create_kwargs.to_create_kwargs_stream().
- rath.llm.normalize_anthropic_response(payload: Mapping[str, Any]) RathLLMChatResponse[source]#
Map an Anthropic
Message-shaped dict toRathLLMChatResponse.payloadis expected to be the result ofmessage.model_dump(mode='json')on the SDK return value (or an equivalent fixture dict). Defending via dict lookups keeps the adapter compatible across minor SDK upgrades.
- class rath.llm.RathLLMChatRequest(*, messages: tuple[~rath.llm.chat_request.RathLLMMessage, ...], model: str | None = None, tools: tuple[~rath.llm.chat_request.RathLLMFunctionTool, ...] | None = None, tool_choice: ~typing.Any | None = None, parallel_tool_calls: bool | None = None, response_format: dict[str, ~typing.Any] | None = None, temperature: float | None = None, top_p: float | None = None, max_completion_tokens: int | None = None, max_tokens: int | None = None, stop: str | list[str] | None = None, n: int | None = None, seed: int | None = None, frequency_penalty: float | None = None, presence_penalty: float | None = None, logit_bias: dict[str, int] | None = None, logprobs: bool | None = None, top_logprobs: int | None = None, reasoning_effort: str | None = None, verbosity: str | None = None, metadata: dict[str, str] | None = None, user: str | None = None, store: bool | None = None, service_tier: str | None = None, extra_create_args: ~typing.Mapping[str, ~typing.Any] = <factory>)[source]#
Maps to keyword arguments passed to the vendor chat API.
model=Nonefalls back tomodelon theProviderheld by the chat client.
- class rath.llm.RathLLMMessage(role: str, content: str | None = None, name: str | None = None, tool_call_id: str | None = None, tool_calls: tuple[Mapping[str, Any], ...] | None = None)[source]#
One
messages[]element for chatcompletions.create.tool_callsis set only for assistant turns in tool-using conversations.
- class rath.llm.RathLLMFunctionTool(name: str, parameters: dict[str, Any], description: str | None = None, strict: bool | None = None)[source]#
A function-style tool definition (
type: function).
- class rath.llm.RathLLMChatResponse(id: str, choices: tuple[RathLLMChatChoice, ...], created: int, model: str, object_type: Literal['chat.completion'] = 'chat.completion', service_tier: str | None = None, system_fingerprint: str | None = None, usage: RathLLMTokenUsage | None = None, raw: Mapping[str, Any] | None = None)[source]#
Normalized non-streaming
ChatCompletion.- property primary_choice: RathLLMChatChoice#
The first choice (typical when
nis 1).
- class rath.llm.RathLLMStreamDelta(content_delta: str | None = None, tool_call_index: int | None = None, tool_call_id: str | None = None, tool_call_name_delta: str | None = None, tool_call_args_delta: str | None = None, finish_reason: Literal['stop', 'length', 'tool_calls', 'content_filter', 'function_call'] | None = None, usage: RathLLMTokenUsage | None = None)[source]#
One chunk emitted by a streaming completion.
Fields are independent and any subset may be populated:
content_deltacarries an assistant text fragment.tool_call_index/tool_call_id/tool_call_name_delta/tool_call_args_deltaextend an in-progress assistant tool_call. Multiple tool calls in one stream are distinguished bytool_call_index.finish_reasonis set on the terminal chunk for a choice.usageis populated only on the final stream event (and only when the underlying API agreed to report it, e.g. OpenAI’sstream_options={"include_usage": True}).
- class rath.llm.RathLLMChatChoice(index: int, finish_reason: Literal['stop', 'length', 'tool_calls', 'content_filter', 'function_call'], message: RathLLMAssistantMessage, logprobs: Mapping[str, Any] | None = None)[source]#
One element of
choices.
- class rath.llm.RathLLMAssistantMessage(role: Literal['assistant'] = 'assistant', content: str | None = None, refusal: str | None = None, reasoning_content: str | None = None, tool_calls: tuple[RathLLMToolCallPart, ...] | None = None, function_call: Mapping[str, Any] | None = None, annotations: tuple[Mapping[str, Any], ...] | None = None)[source]#
Assistant message on a choice (content, optional tool calls, provider extras).
- class rath.llm.RathLLMToolCallPart(id: str, type: str, function: RathLLMToolCallFunction)[source]#
One entry from
message.tool_calls.
- class rath.llm.RathLLMToolCallFunction(name: str, arguments: str, arguments_parsed: dict[str, Any] | None, arguments_parse_error: bool)[source]#
functionpayload inside a tool call (name + arguments string).
- class rath.llm.RathLLMTokenUsage(prompt_tokens: int, completion_tokens: int, total_tokens: int, completion_tokens_details: Mapping[str, Any] | None = None, prompt_tokens_details: Mapping[str, Any] | None = None)[source]#
Token counts from
usage; optional detail dicts stay JSON-shaped.
- rath.llm.add_usage(a: RathLLMTokenUsage | None, b: RathLLMTokenUsage | None) RathLLMTokenUsage | None[source]#
Sum two token usages.
Returns
Noneonly when both inputs areNone(so callers can detect that no provider in the chain reported usage). Detail dicts are not merged - they are dropped on the accumulated total because per-call breakdowns don’t sum cleanly.
- exception rath.llm.BudgetExceededError[source]#
Raised by user code from
Provider.on_budget_exceededto abort a loop.The session loop itself does not raise this automatically when
budget_total_tokensis exceeded — it only invokes the callback (or logs a warning if no callback is set). Raising this from the callback is the documented way to stop the loop on overrun.