LLM#
OpenRath uses registry-dispatched chat clients. The default kind is OpenAI-compatible; provider_kind="anthropic" selects the Anthropic adapter. v1.2 also adds embedding and VLM provider wrappers for memory and visual-model use cases. Advanced integrations can register a new chat client kind or replace SessionLoopExecutor to take over model calls, response parsing, and tool dispatch.
This page explains how OpenRath builds provider requests, normalizes responses, streams deltas, accounts for token usage, and replaces the client or executor.
The diagram below places Provider in the request path. Provider options,
session messages, and FlowToolCall schemas become one OpenAI-compatible chat
request; the normalized response is written back into the session loop.
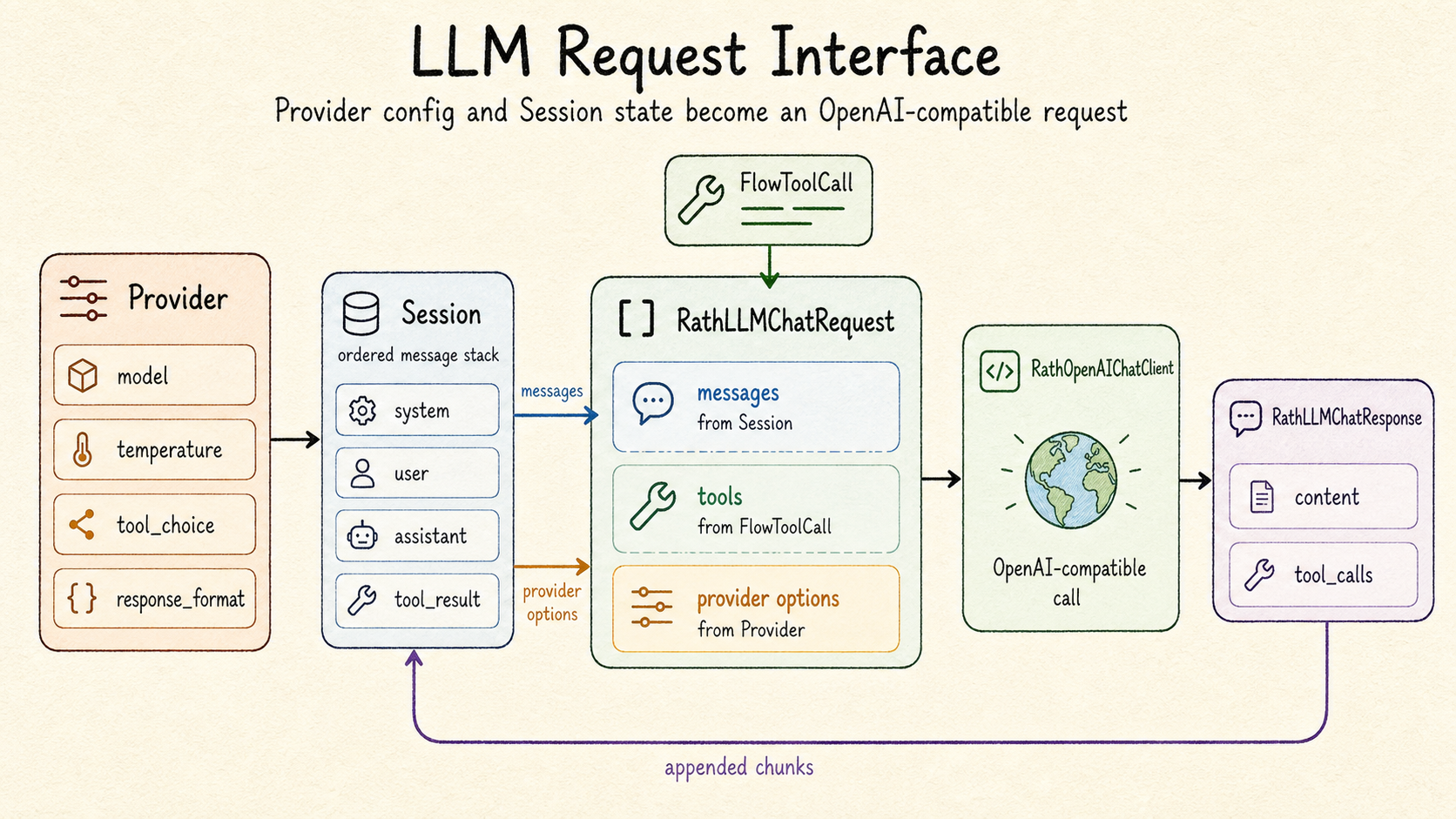
Provider configures the request, while Session supplies messages and
FlowToolCall supplies tool definitions.#
Overview#
The LLM layer is deliberately narrow. It does not own workflow state and it does not execute tools. Its job is to carry provider options, build a request, call an OpenAI-compatible client, normalize the response, and hand the result back to the session loop.
Source map#
File |
Responsibility |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Request dataclasses. |
|
Normalized response and stream-delta dataclasses. |
|
Conversion from internal request to OpenAI SDK kwargs. |
|
Conversion from OpenAI completion to internal response. |
|
Conversion from internal request to Anthropic kwargs. |
|
Conversion from Anthropic response to internal response. |
|
Default |
Provider Parameters#
Provider is the request options object. It stores the API key, optional base URL, model name, sampling parameters, tool choice, response format, and passthrough arguments.
import os
from rath.llm import Provider
provider = Provider(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ.get("OPENAI_BASE_URL") or None,
model=os.environ.get("OPENAI_DEFAULT_MODEL") or "gpt-5.5",
temperature=0.2,
parallel_tool_calls=False,
)
provider_into_chat_request(...) merges Provider into RathLLMChatRequest. The session loop builds messages and tools. Provider.from_config(...) can also load named providers from ~/.openrath/config.json; explicit kwargs override the config entry.
Default Client#
chat_client_for(provider) chooses a built-in adapter or a registered third-party adapter.
|
Client |
|---|---|
|
|
|
|
RathOpenAIChatClient wraps openai.OpenAI(...).chat.completions.create(...); legacy Azure endpoints use openai.AzureOpenAI. RathAnthropicChatClient wraps anthropic.Anthropic(...).messages.create(...).
Environment variable |
Purpose |
|---|---|
|
API key for OpenAI or a compatible gateway. |
|
OpenAI-compatible endpoint. |
|
OpenAI-compatible fallback model. |
|
Azure endpoint fallback. |
|
Azure key fallbacks. |
|
Anthropic API key. |
|
Anthropic endpoint override. |
|
Anthropic fallback model. |
Config fallback comes after explicit Provider fields and environment variables. The OpenAI client looks for provider_kind="openai" config entries; the Anthropic client looks for provider_kind="anthropic".
Streaming#
OpenAI-compatible and Anthropic streaming are exposed through run_session_loop(on_event=...). The loop builds a StreamingExecutor around a StreamingChatClient, forwards every RathLLMStreamDelta to the callback, and appends one accumulated assistant chunk per model round.
Third-party chat clients that implement only complete(req) still work for non-streaming calls. Passing on_event with a non-streaming client raises TypeError before the loop registers sessions.
Embedding And VLM Providers#
Embedding and VLM wrappers deliberately sit beside chat providers instead of overloading Provider.
Provider |
Main use |
Config key |
|---|---|---|
|
Vectorizing text for memory backends and retrieval. |
|
|
OpenAI-compatible embeddings endpoint. |
Uses the embedding provider fields. |
|
Vision-language requests. |
|
|
OpenAI-compatible image/text model endpoint. |
Uses the VLM provider fields. |
EmbeddingProvider.from_config(...) can reuse credentials from llm.default_provider and defaults to text-embedding-3-small when the model is omitted. VLMProvider.from_config(...) is stricter and expects an explicit VLM provider or overrides, because a chat default is not necessarily image-capable.
SessionLoopExecutor#
SessionLoopExecutor is the replacement point for the loop.
class SessionLoopExecutor(Protocol):
def complete(self, req: RathLLMChatRequest) -> RathLLMChatResponse:
...
def dispatch_tool(self, session, tool, arguments):
...
def tool_schemas(self):
...
Method |
Purpose |
|---|---|
|
Runs one chat completion. |
|
Executes a |
|
Returns tool schemas; when it returns an empty tuple, the loop builds schemas from the local tool table. |
DefaultSessionLoopExecutor uses chat_client_for(agent_provider) for model requests and directly calls tool(session, arguments) for tool execution.
Requests And Responses#
OpenRath uses normalized dataclasses internally:
Type |
Purpose |
|---|---|
|
messages, tools, model, sampling parameters, and extra args. |
|
Normalized completion. |
|
Normalized streaming content/tool-call/usage delta. |
|
system/user/assistant/tool message. |
|
OpenAI-style function tool schema. |
|
Prompt/completion/total token usage. |
Integration Points#
Need |
Extension point |
|---|---|
Change OpenAI-compatible gateway |
Set |
Change model and sampling parameters |
Set |
Use a local model service |
Implement |
Customize tool dispatch policy |
Implement |
Test fixed model responses |
Use a scripted executor. |
Call Anthropic ( |
|
Stream assistant deltas |
Pass |
Configure embeddings |
Set |
Configure VLM calls |
Set |
Wire an MCP server’s tools |
|
Per-session token accounting |
|
Token budget guardrail |
|
Register a new provider |
|
Call Path#
Default session loop LLM call path:
run_session_loop
-> provider_into_chat_request(messages, tools, Provider, default_tool_choice="auto")
-> DefaultSessionLoopExecutor.complete(req)
-> chat_client_for(provider).complete(req)
-> provider-specific create kwargs
-> provider SDK call
-> provider-specific response normalization
The compress path uses the same client and request/response DTOs, but passes tools=None and default_tool_choice="none".
Edge Cases#
Behavior |
Current implementation |
|---|---|
missing API key |
Built-in clients raise |
missing model |
Provider-specific create-kwargs builders raise |
streaming |
Built-in OpenAI-compatible and Anthropic clients support |
tool argument parsing |
|
empty choices |
|
token budget |
The guard fires only on the first completion that crosses |
Test Coverage#
Behavior |
Tests |
|---|---|
request/response wire shape |
|
live OpenAI-compatible client |
|
OpenAI streaming chunks |
|
Anthropic adapter and streaming |
|
embedding/VLM wrappers |
|
provider registry |
|
scripted loop executor |
|
integration loop/compress |
|